
La popularidad de Ciencia de Datos también tiene desventajas. La principal desventaja es que la precisión de lenguaje que se valora dentro del ámbito académico, se relaja un poco (a veces un montón). Y de esa forma cuesta a veces saber de que se esta hablando. Así que en este podcast vamos a buscar una forma para poder organizar y estructurar un poco los conceptos que se usan en la ciencia de datos. Vamos a tratar de armar un esquema que nos pueda servir como punto de referencia para ir poniendo los temas y las metodologías que vamos discutiendo en contexto.
Nos imaginamos el total de las posibilidades de análisis como un cubo con tres dimensiones. Por un eje ponemos el objetivo, lo que quiero hacer y lo llamamos Yo Quiero. Quermos por ejemplo comparar, agrupar, reconocer, predecir, o asociar. Por el otro eje ponemos las características principales del las variables: Mis Datos Son. Por ejemplo, mis datos pueden ser: continuos, ordinales, nominales, espaciales, palabras y/o imágenes. Como tercer y último eje, para terminar de hacer el cubo, podemos poner las características del conjunto de datos que estamos trabajando: Mis Datos Tienen. Los datos en conjunto tienen cierto volumen, variedad, velocidad, veracidad y valor.
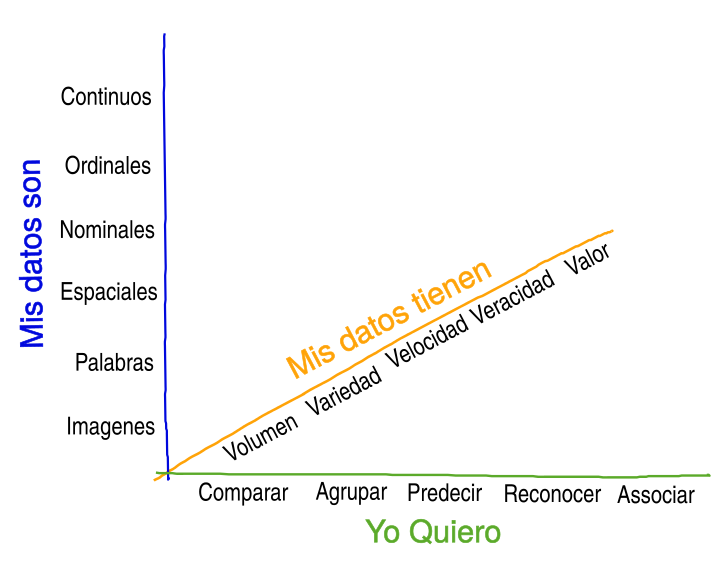
Claro que con esto acabamos de hacer 5 * 6 * 5 compartimentos, con un gran total de 150. No todos los compartimentos contienen metodologías especificas, y hay mucho solape. Pero seguramente nos tomará mas de 30 minutos repasarlos todos. Ademas, la dimensión de Mis Datos Tienen indica diferencias en aproximaciones que son diferentes a nivel de infraestructura tecnológica como de metodología de análisis.
Así que nos enfocamos en dos de tres dimensiones: lo que quiero y las características de los datos. Pero antes de dejarlos a un lado, repasemos las características de los conjuntos de datos. Mas porque este eje Mis Datos Tienen, contiene la definición de lo que se considera "Big Data". Las caracteristicas sobre este eje los llaman también las 5 uves. Hay quienes hablan de tres, cuatro o hasta 7 uves, pero muchos coinciden en que las principales son Volumen, Variedad, y Velocidad.
Volumen: cuantos puntos de medición hay, o cuantos bytes si se tratan de texto o imágenes. Los problemas se dan cuando hay mas datos de lo que cabe en la memoria del computador que estas usando, o peor, mas de lo que cabe en el disco duro de tu servidor. Por el otro lado también hay problemas cuando el volumen es muy bajo y tienes pocos datos y muchas preguntas.
Variedad: Entre mas homogéneo sean las variables, mas fácil es trabajarlos. Por ejemplo si solo tengo datos numéricos, o mejor aún solo datos numéricos continuos tengo mas posibles metodologías a si tengo 100 GB de texto con comentarios en palabras en 40 lenguajes. O si tengo un a mezcla de datos numéricos, texto, vídeo e imágenes. Entre mas diferentes son los tipos de variables en mis conjunto de datos mas alta la variedad.
Velocidad: Cuando datos se generan continuamente y fluyen con cierta velocidad (EN: streaming data) se requiren soluciones especiales. Cuando la velocidad es baja, podríamos por ejemplo re-calcular el promedio de una variable a ciertos intervalos. Pero cuando la velocidad del flujo de información incrementa, muy pronto ya no tenemos la velocidad de calculo disponible para recalcular con todos los datos en tiempo real.
Después de estas tres uves vienen mas dependiendo con quien hablas. En nuestra opinión vale la pena destacar dos mas: Veracidad y Valor
Veracidad: Que tan confiables son los datos que tenemos (que sabemos de antemano). Por ejemplo, si uso datos experimentales, voy a tener la mayor confianza en mis datos si hago el experimento yo mismo. Si le pido a 20 personas al hazar de repetir el experimento es posible que la confiabilidad (a priori) de los datos sea mas baja. Algunas personas quizás no entendieron el experimento, o se inventan resultados para poder entregar mas rápido. Igual pasa en ciencia de datos, sobretodo en datos de empresas grandes, donde a veces ya nadie sabe la proveniencia de datos, o se trata de encuestas donde no todos los respondientes tienen un interes en responder con precisión.
Valor: Hay conjuntos de datos que han costado millones de dolares en reunir (valor en dinero). O donde un solo punto extra, cuesta días, meses o mas en conseguir (valor en tiempo). Tambien hay análisis donde un error puede resultar en perdidas de millones.
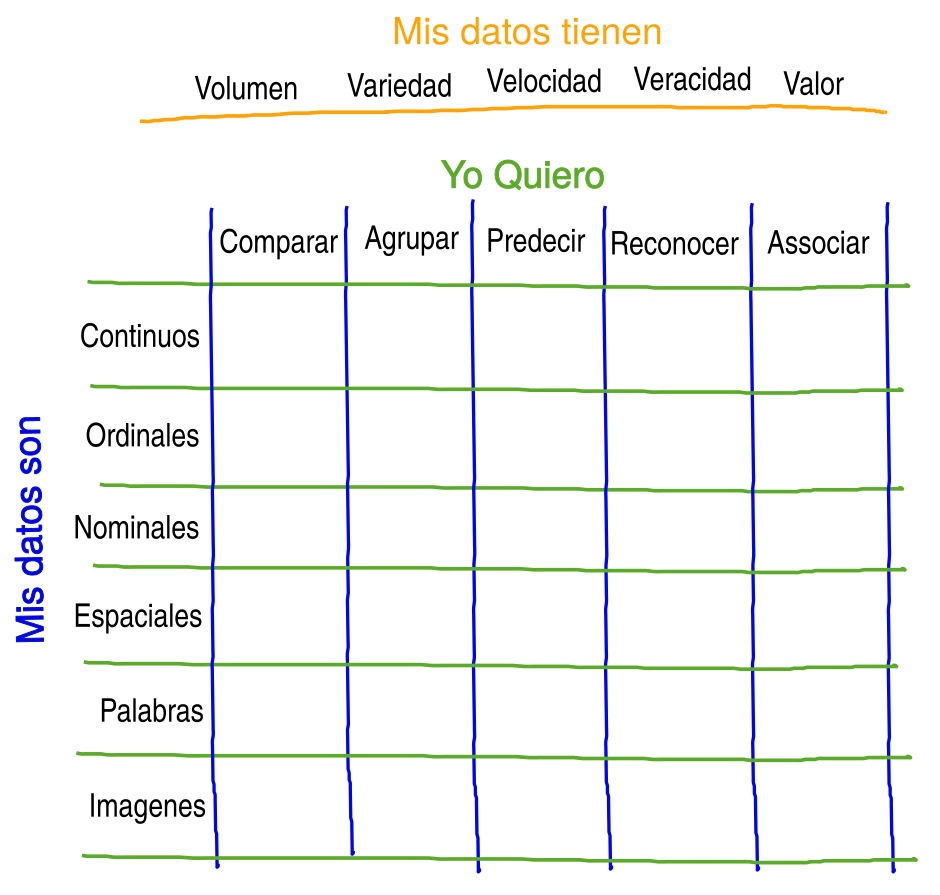
Aún quedando con la matriz de lo que quiero las caracteristicas de los datos (como arriba), nos queda un mundo de posibles metodologías y aproximaciones por explorar. Afortunadamente tenemos muchos Data Latam Podcasts por delante para ir rellenando cada cuadrado en la matriz arriba con metodologías y aproximaciones. Ademas hablaremos de características aún mas técnicas de variables como homoscedasticidad, el tipo de modelo que aplica (unimodal, bimodal, linear), distribuciones normales y otras que dan a técnicas no-para métricas. Quizás en un podcast donde nos enfocamos en términos y conceptos de estadísticas.
El esquema arriba tiene mucho campo para mejorar, y nos encantaría hacerlo contigo. Si vez un error o tienes una idea de como mejorarlo escríbenos en Twitter @datalatam o en Facebook @datalatam.
Otros recursos:
Hay muchos recursos sobre este tema en linea como por ejemplo este infografico de IBM. Pero para estructurar las posibilidades metodologicas para hacer análisis uno de los mejores libro es: Data Mining, concepts and techniques de Jiawei Han, Micheline Kamber y Jian Pei.